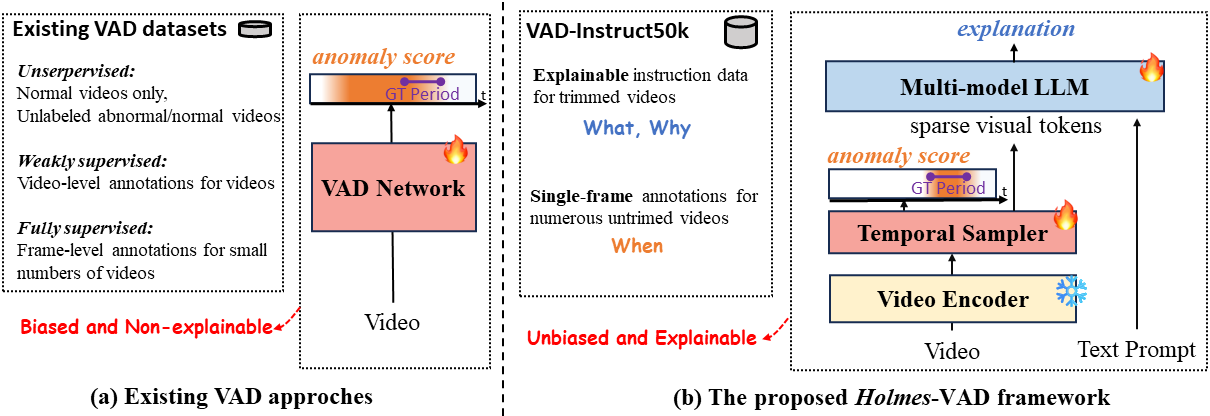
Towards open-ended Video Anomaly Detection (VAD), existing methods often exhibit biased detection when faced with challenging or unseen events and lack interpretability. To address these drawbacks, we propose Holmes-VAD, a novel framework that leverages precise temporal supervision and rich multimodal instructions to enable accurate anomaly localization and comprehensive explanations.
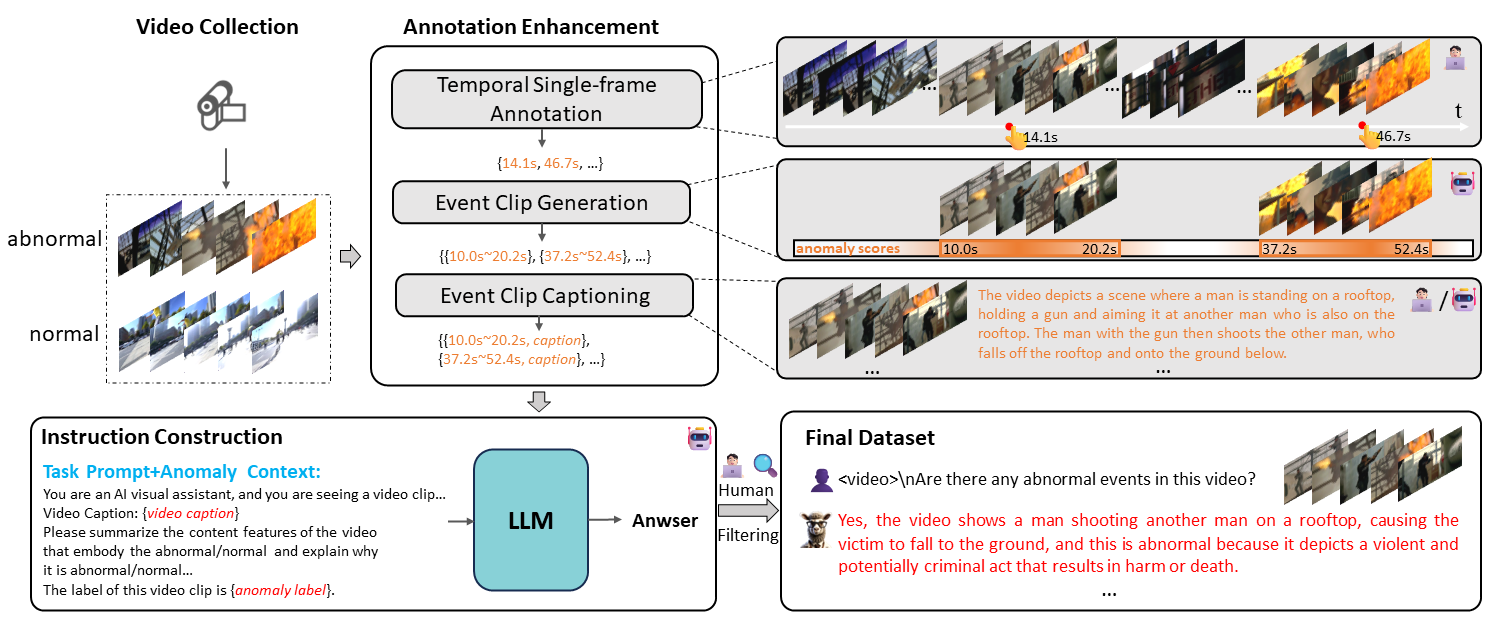
We construct the first largescale multimodal VAD instruction-tuning benchmark, i.e., VAD-Instruct50k. This dataset is created using a carefully designed semi-automatic labeling paradigm. Efficient single-frame annotations are applied to the collected untrimmed videos, which are then synthesized into high-quality analyses of both abnormal and normal video clips using a robust off-the-shelf video captioner and a large language model (LLM).
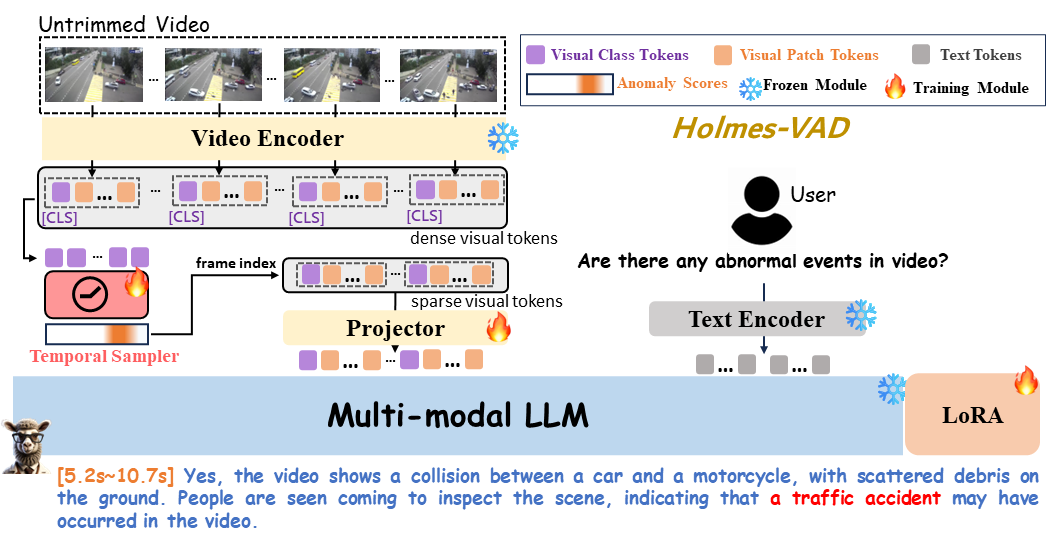
Building upon the VAD-Instruct50k dataset, we develop a customized solution for interpretable video anomaly detection. We train a lightweight temporal sampler to select frames with high anomaly response and fine-tune a multimodal large language model (LLM) to generate explanatory content.
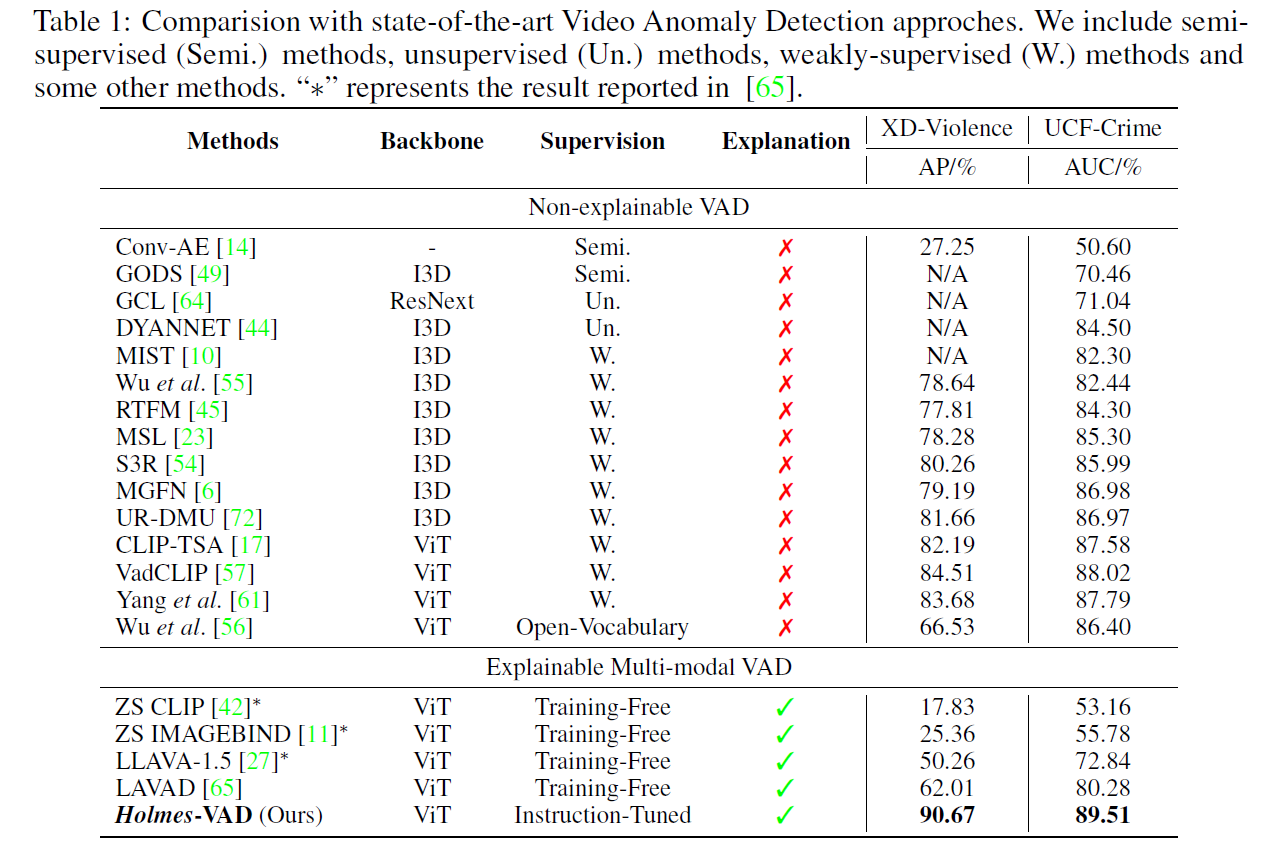
In this section, we conduct extensive experiments to thoroughly demonstrate the capabilities of our proposed model, i.e., Holmes-VAD.

@article{zhang2024holmes,
title={Holmes-VAD: Towards Unbiased and Explainable Video Anomaly Detection via Multi-modal LLM},
author={Zhang, Huaxin and Xu, Xiaohao and Wang, Xiang and Zuo, Jialong and Han, Chuchu and Huang, Xiaonan and Gao, Changxin and Wang, Yuehuan and Sang, Nong},
journal={arXiv preprint arXiv:2406.12235},
year={2024}
}